
If you’ve collected feedback before, then you know that making sense of responses to your open-ended questions can be challenging. But more than 40% of SurveyMonkey surveys include open-ended questions, and we recommend them because text responses often show you a more complete picture of your customers, employees, or prospects.
Analyzing this type of qualitative data can be laborious even for advanced market research firms. It involves reading through the feedback, searching for keywords, and organizing responses in a way that allows you to make quantitative claims. SurveyMonkey’s suite of text analytics tools help accelerate the process of generating valuable insights from text responses through automatically-generated insights that can be customized as desired..
Introducing: rule-based tagging
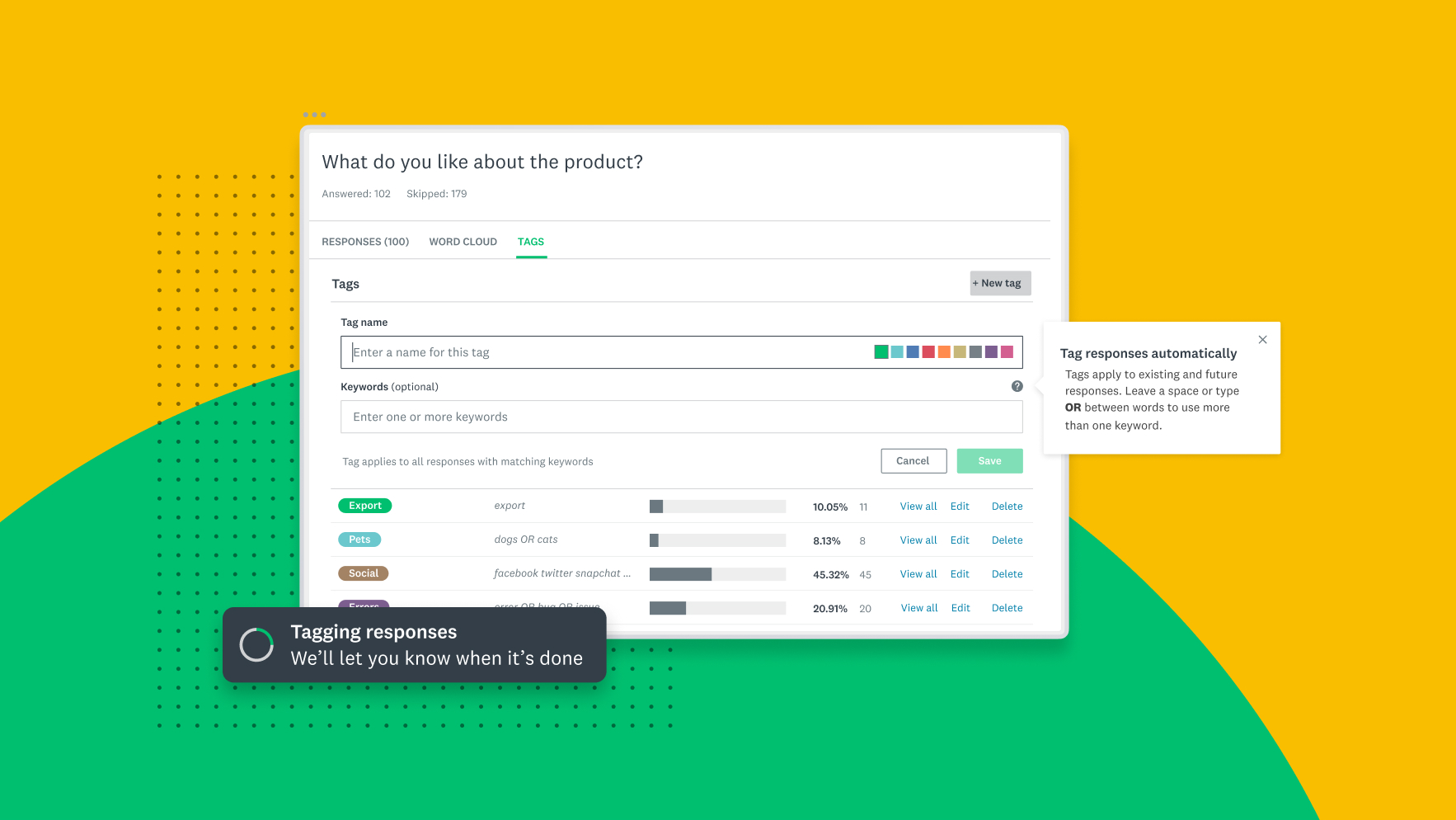
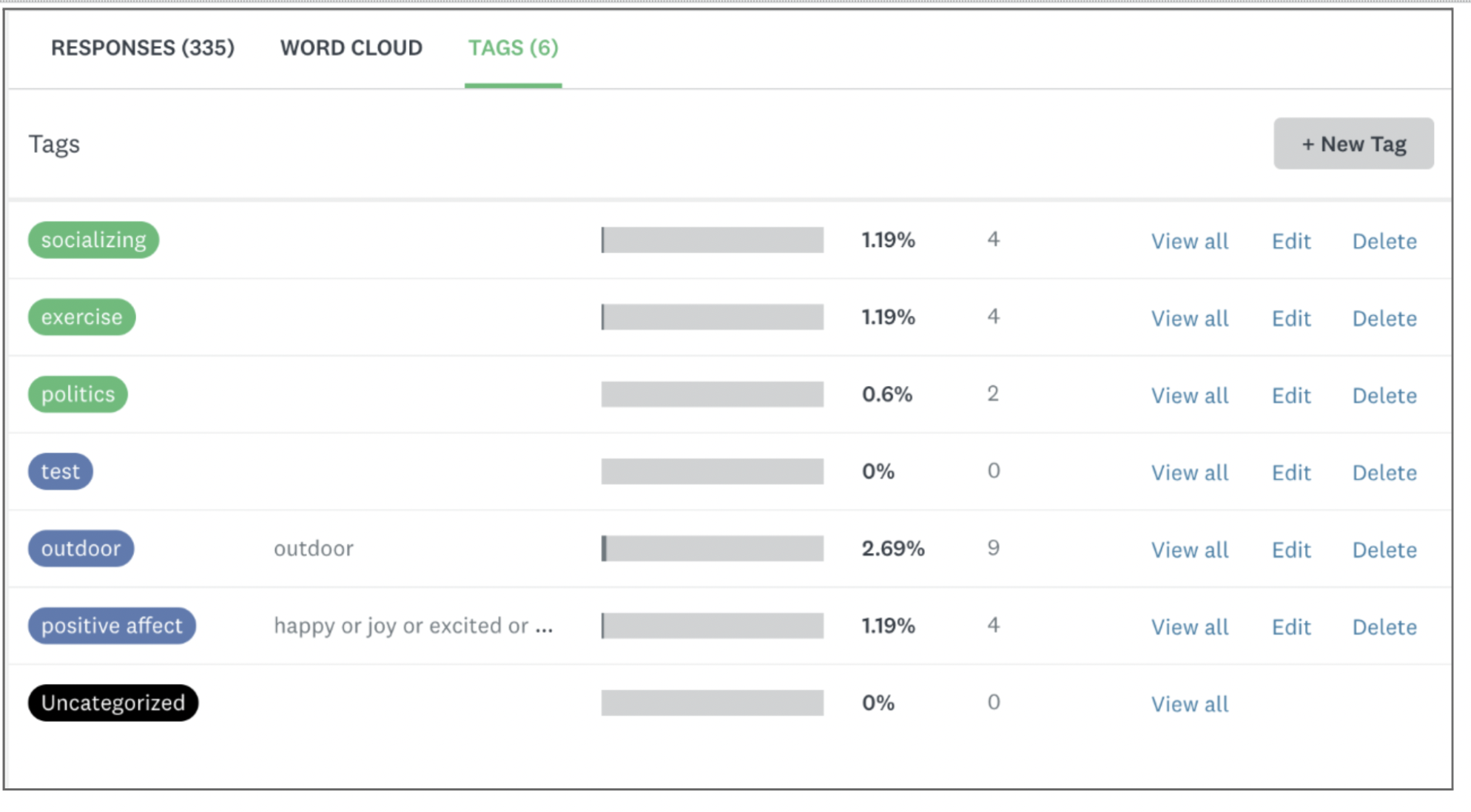
With the launch of rule-based tagging for SurveyMonkey Enterprise plans, the process of tagging responses with key themes or topics is easier than ever. In addition to having the option to manually tag open-ended responses, you can now use rule-based tagging to automatically tag responses that meet criteria you specify. For example, you could set a rule to tag responses that include certain phrases or keywords, a combination of keywords or phrases, or even those that start with certain words or letters.
Let’s say you wanted to tag all responses that contained references to customer support. You could create a rule to automatically tag all existing and future responses that include the keywords “customer support” OR “service” OR “agent”, with a “customer support” tag. . For the full syntax available for rules and more about how to use this new feature, check out our Help Center article.
Rule-based tagging is a powerful way to accelerate feedback analysis, identify common trends or patterns, and more easily supplement quantitative data with qualitative insights—especially when used in conjunction with our existing suite of text analytics capabilities, which can help you:
- Quickly identify respondent sentiment—using machine learning and natural language processing (NLP), sentiment analysis reads through the responses to your open-ended questions and automatically categorizes them as positive, neutral, or negative. You can view the distribution of these categories overall, or filter responses by sentiment to get a deeper understanding of how certain respondents feel.
- Create visualizations of text responses—Word Cloud will display the most frequently-used words in your text responses, making it easier to identify trends. Also powered by machine learning, our Word Cloud can understand the rules of grammar such as plural vs. singular words, present and past tense, abbreviations, and even emojis!
- Filter question summaries by responses containing one or more keywords – You can also choose to filter all question summary visualizations by keyword(s) in a text response to uncover patterns in how those respondents answered other questions on the survey.
Questions that let respondents reply in their own words can help uncover valuable information—and SurveyMonkey’s powerful text analysis tools help you to easily cut through the clutter and avoid labor-intensive efforts to understand meaningful trends and patterns. Use rule-based tagging, manual tagging, sentiment analysis, and Word Clouds to get to that “ah-ha” moment in just a few clicks.


